A Guide to JavaScript Fuzzy Search Libraries
Regular Expressions (Regex) have taken string parsing to a whole new level. Previously, you had to iterate over each character and perform complex computations to locate matches. Regular Expressions have made their way into just about every programming languages from SQL to PHP, thus allowing for more fine-grained searching. Blame it on Google, but today’s web surfers want even more. Now they expect the search process to know what they mean even when they themselves aren’t sure that they are looking for. That’s where fuzzy searching comes in. Writing your own fuzzy search would probably take a lot of work, so why not capitalize on libraries written expressly for that purpose? In today’s article, we’ll review a few such libraries for JavaScript that help you to perform complex searches on the client-side.
Fuzzy Searching and the Levenshtein Distance
Generally speaking, a fuzzy search returns a number of matches that are likely to be relevant to a search term or terms even when the match does not exactly correspond to the search term(s). In some ways a fuzzy matching program can operate a lot like a spell checker. For example, if a user enters “John”, the list of hits returned may contain alternative spellings such as “Jon” or “Johnny”, as well as words that sound the similar but are spelled differently. One of the primary catalysts for fuzzy searching (besides Google) was to compensate for errors caused by optical character recognition ( OCR ) document scanning.
So how does one implement such a search? One way is to measure something called the Levenshtein distance. That’s a string metric for measuring the difference between two character sequences. It produces an integer value that represents the minimum number of single-character edits (i.e. insertions, deletions or substitutions) required to change one word into the other. It is named after Vladimir Levenshtein, who came up with the metric in 1965. For example, the Levenshtein distance between “kitten” and “sitting” is 3, because of the first letter, fifth letter, and the extra g at the end of “sitting”.
Another approach is to use a SOUNDEX function. Soundex is a phonetic algorithm for indexing names by sound, as pronounced in English. The goal is for syllables to be encoded to the same representation based on sound so that they can be matched despite minor differences in spelling. The function returns a key string that is 4 characters long, starting with a letter. Words that are pronounced similarly produce the same soundex key, and can thus be used to simplify searches where you know the pronunciation but not the spelling. Both Transact-SQL and PHP have implementations of the SOUNDEX function. The latter is based on one by Donald Knuth in “The Art Of Computer Programming, vol. 3: Sorting And Searching”, Addison-Wesley (1973), pp. 391-392.
Why Fuzzy Search in JavaScript
While JavaScript is not the right language for parsing millions of records – that’s best left to SQL or server-side languages like Java or PHP – it can yield excellent performance on smaller record sets. For example, searching over 2 keys in 20,000 records might take approximately 1 second for one of the libraries listed here today. You wouldn’t want to go much beyond this anyway because all of this data must be downloaded to the client. Even with a compact transfer mechanism like JSON, it could take some time, depending on connection speed. It’s a great way to whittle down a list of items like countries, states/provinces, or cities. A Lot of sites provide auto-completion, but only with exact spelling. Adding fuzzy searching can fix a lots of typos and misspellings.
The Libraries
Unless you’re a really hard core developer, it’s probably best to employ a library to do your fuzzy matching. The rest of this article describes some JS implementations.
Fuse.js
Our first library was written by Kiro Risk, a Software Engineer at LinkedIn. Fuse.js is lightweight (1.58 kb minimized) and uses a full Bitap algorithm, an implementation of the Levenshtein distance and is based on the Diff, Match & Patch tool by Google.
It supports the searching of simple arrays to deep key matching within complex objects. In the case of the latter, more than one key field may be searched. The search function may be configured to return the matching objects or just indices.
The degree of fuzziness is set using a threshold from 0.0 to 1.0 whereby 0.0 requires a perfect match (of both letters and location) and a threshold of 1.0 would match anything.
var books = [{
id: 1,
title: 'The Great Gatsby',
author: {
firstName: 'F. Scott',
lastName: 'Fitzgerald'
}
},{
title: 'The DaVinci Code',
author: {
firstName: 'Dan',
lastName: 'Brown'
}
}];
var options = {
keys: ['author.firstName']
}
var f = new Fuse(books, options);
var result = f.search('brwn');
==>
[{
title: 'The DaVinci Code',
author: {
firstName: 'Dan',
lastName: 'Brown'
}
}];
Matt York’s Fuzzy Search
Matt York modeled his 1k standalone Fuzzy Search library after the Textmate and Sublime Text editors’ fuzzy file search capabilities. It can be utilized via Node.js or within the browser. The text editor influence becomes apparent when you see that it can highlight the results using HTML tags.
One of the pages in the examples folder performs a search for movie directors that is bound the the onkeyup event. There is quite a long list of directors, but here is a sample of the directors array’s contents:
var directors = [{dir:'John Sedlar', fb:'/m/05x5_p2',movies:'Gospa'}
,{dir:'Margien Rogaar',fb:'/m/04zlzb0',movies:'Aliento'}
//...
];
The lookup is accomplished via the fuzzy.filter() function. It accepts the search term(s), the list, as well as an options object. Configurable options include the tags to surround matches with as well as a function that returns the attribute to search on. Each part of the results is displayed using a template.
function displayResults() {
var search = $('#search').val();
var options = {
pre: "<b>"
, post: "</b>"
, extract: function(entry) {
return entry.dir;
}
}
var filtered = fuzzy.filter(search, directors, options);
var results = filtered.slice(0,50).map(function(result){
var items = result.string.split('::');
return listItemTemplate({
freebase: result.original.fb
, director: result.string
, movies: result.original.movies
, score: result.score
});
});
$('#lists').html(results.join(''));
$('#result_size').html(results.length);
}
Here is a screenshot of the directors.html page in action:
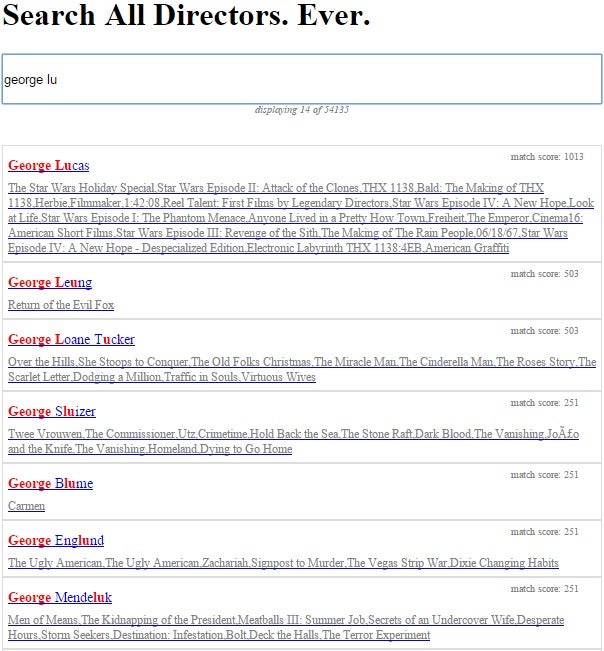
Conclusion
Give those two libraries a try and see what you think. There are more to come!











